 Mithril
Mithril
Task based vs CRUD based in API
Task based and CRUD based are two different approaches you can encounter when you’re using an user interface. But besides the UI itself, you also have to choose between the same options when you build your API.
While task based is widely adopted when we talk about UI, it’s not always the case when we talk about the API.
In this post, I will present you what’s the difference between task based and CRUD based plus the benefits/drawbacks of each.
For each approach, let’s imagine our application will manage some contracts (Original, isn’t it?). Each contract will have those fields:
- Contract number
- Contract holder name
- Start date
- End date
- Status (Active, Closed, Pending)
- Closing reason (Unsatisfied, Relocation, Dead)
This post is widely inspired by the Greg Young’s CQRS document so if you’ve already read it, you will find a lot of similarities.
CRUD based is probably the simplest approach. It stands for ‘Create-Read-Update-Delete’. In such approach, your UI will display all the available fields and let the user decide what to update:
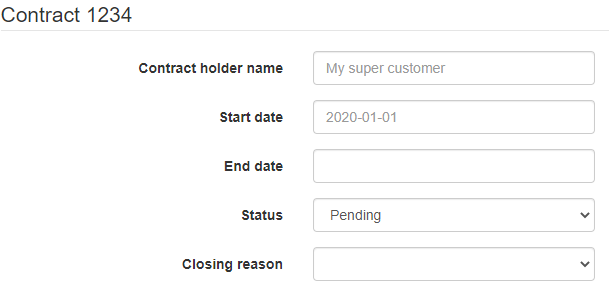
This interface will let the user be completely free and unguided about how to do something. The UI to create, read or update the data will probably be more or less the same and it will also be the case for the model exposed by the API.
So if you want to update you have to get the data, change the field you need and send all the fields back to the API:
{
"ContractNumber": "1234"
"ContractHolderName": "MySuperCustomer",
"StartDate": "2020-01-01"
"EndDate": null,
"Status": "Active"
"ClosingReason": null,
}
But if you need to do a specific action like closing the contract, you have to know/remember you need to set the status to “Closed”, set a closing reason and set a valid end date.
Obviously the UI can help you by marking those fields as mandatory when you edit the status but it’s reactive. You have to know you need to update the status to see what are the other needed fields.
With the task based approach, you will decompose your UI (and your API) to match to the different tasks (= actions) the user can do. In our example: what can the user do?
- Modify the contract holder name.
- Close the contract.
- Activate/Open the contract.
- Reopen the contract after it was closed.
In this case, there is not a lot of tasks but they will probably increase with the number of fields.
In the task based approach (on the UI side), you will display the information and propose to the user to execute an action by displaying some buttons. Obviously only the available actions will be displayed.

Once the button is clicked (= when the user shows he wants to do some action), a wild form appears containing only the field(s) he needs to fill in to execute the action.
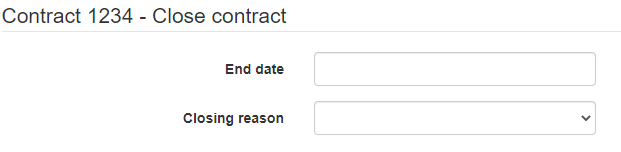
In this case, the read model exposed by the API will look like the one in the CRUD approach but the update model will be divided in as many possible actions.
In the case of a contract closing:
{
"EndDate": "2020-12-31",
"ClosingReason": "Relocation",
}
Note: the “Status” field is not needed. Since the user’s action is explicit, the new status can simply be set in the backend and adding the status could only lead to inconsistency (What if someone add the status with an invalid value like “Active”? It wouldn’t make any sense regarding the action we are trying to achieve here).
Data that the backend can deduce/retrieve should not be sent.
So let’s compare both of them from an API point of view.
Obviously the CRUD based will be more effective to develop. Since it will be a single model for every operation (read/update/delete) and if your API is generic enough, it should be really easy to add new models. In fact, you could also drop your own API and use some storage like Firebase or Azure Cosmos DB because those provide directly some API to do some CRUD operations.
From the API developer point of view:
You will only receive a model with the few fields needed for your action instead of the whole model. It will be easier to validate because you don’t have to check all the possibilities.
From the API consumer point of view:
You probably encountered some API where you have a model with dozens or hundred of lines and you don’t know which field you’re a supposed to fill in to complete what you want? So you first have to read the documentation to know, depending on your action, which field should be modified (Status) and then, based on that, which other field(s) should be modified (EndDate, ClosingReason).
Documentation is meant to be read but in this case, it could easily be avoided if the exposed model was speaking for itself.
If you have to reach and endpoint like “…/close” (not really REST like of course) and provide this model :
{
"EndDate"; ...,
"ClosingReason": ...,
}
There is no need for additionnal documentation here, you know what you’re doing and which information you need to provide as the model is guiding you.
Sometimes, you will maybe be tempted to add more fields… maybe those could be deduced (here the status) or retrieved by the backend but since you know the API will need the information and you already have it on your side, you may think it’s a good idea to provide it. You should avoid it in almost all cases. In order to gain some performance, you will sacrifice some readibility and some security. Remember the golden rule: Never trust user input.
You should put yourself in a position where you did not develop the API but you need to use it. Is it clear enough to be used like that?
For each field, you should ask yourself those questions:
- Can this field be deduced by the API ?
- Can this field be retrieved by the API based on previously provided information ?
- Won’t this field be useful to decide something or update/write some data ?
If the answer to one of those question is “yes”, you should seriously reconsider to add this field.
When the user send a, action to close the contract, you perflectly know what the user wants to do: You know their intent.
How do you differentiate incoming actions? It could be an enum but it will probably be a different endpoint if you’re using REST or a different procedure if you’re using something like gRPC.
In CRUD based, you can only deduce it by loading the data from the storage and compare field by field which one has been changed:
public void Update(Contract contract)
{
var oldContract = _contractRepository.GetByContractNumber(contract.ContractNumber).
if (oldContract == null)
{
throw new Exception("No corresponding contract found");
}
if (oldContract.ContractHolderName != contract.ContractHolderName)
{
// In this case the user wanted to update the name
}
if (oldContract.Status != contract.Status)
{
// In this case the user wanted to close/open the contract.
if (contract.Status == ContractStatus.Active)
{
// The user want to open/reopen the contract
if (oldContract.Status == ContractStatus.Pending)
{
// The user want to activate the contract
// for the first time
}
else if (oldContract.Status == ContractStatus.Closed)
{
// The user want to reopen the contract
}
}
else if (contract.Status == ContractStatus.Close)
{
// The user want to close the contract. We have to check if the fields "EndDate"
// and "ClosingReason" are filled.
}
}
}
Where in task based, you will get something like this:
public void CloseContract(CloseContractCommand command)
{
// ...
}
public void OpenContract(OpenContractCommand command)
{
// ...
}
public void ReopenContract(ReopenContractCommand command)
{
// ...
}
The intent is crystal clear for everyone.
Here the “XXXCommand” is the model representing your action. Action/Command/Task are synonyms in this case but while “task” or “action” are priviledged in the UI world, “Command” is the most used in the API world.
By the way, commands names could (should) correspond to business’s use cases. The business will never say “when the user put the status to ‘closed’ and…” it will just say “when the user close the contract”. It’s really precious to keep those command’s name as close to the business language as possible.
This one is a side effect of the “smaller model” characteristic.
The lost update is a well known issue when we talk about concurrency. In short, if you do not have some locking mechanism (optmistic or pessimistic) and two updates arrive at the same time, the second one will win and erase data from the first one.
Let’s say two peoples launch the application at the same time and get the contract. While the first user update the holder name and close the application, the second user will let the application opened for a few minutes (or hours) then will close the contract. In CRUD based, since all fields are sent, the initial value for the contract holder is sent with all the fields and will override the first user’s action.
Task based approach will not solve the whole lost update issue but it will at least limit the impact. In the previous example, since the two updates are about two different actions, no data would be lost. The first update would just update the name and the second will just update the fields related to the contract closing (end date, status, closing reason)
This one is a side effect of the “we know the intent” characteristic.
In case you need to secure your API for high level actions (update contract, create contract, …), the CRUD based will not be an issue.
But imagine you want to bring that granularity to actions (some users could be able to close a contract, some could be able to reopen a contract and some could only be able to update the holder name): With a CRUD based, it will be difficult to achieve that with your framework (for example with the “AuthorizeAttribute” from ASP.NET Core). You’ll have to make some storage calls and some checks to define which action the user wanted to do. And it’s possible the user was trying to do multiple actions at once.
Since in a task based approach each action could reach a different endpoint, such granularity is way easier to achieve.
As always in the IT world, the answer for “which one should I choose for my API?” is “it depends”.
If you really need a basic CRUD API to allow your user to modify data with no specific/complex rules you should really go for the CRUD based API… Or preferably use a storage that will directly provide such API and you won’t need to build the API at all!
While CRUD based is really simpler at first and easier to learn, the more you will add some business logic to your application the more complex it will be to add/modify features.
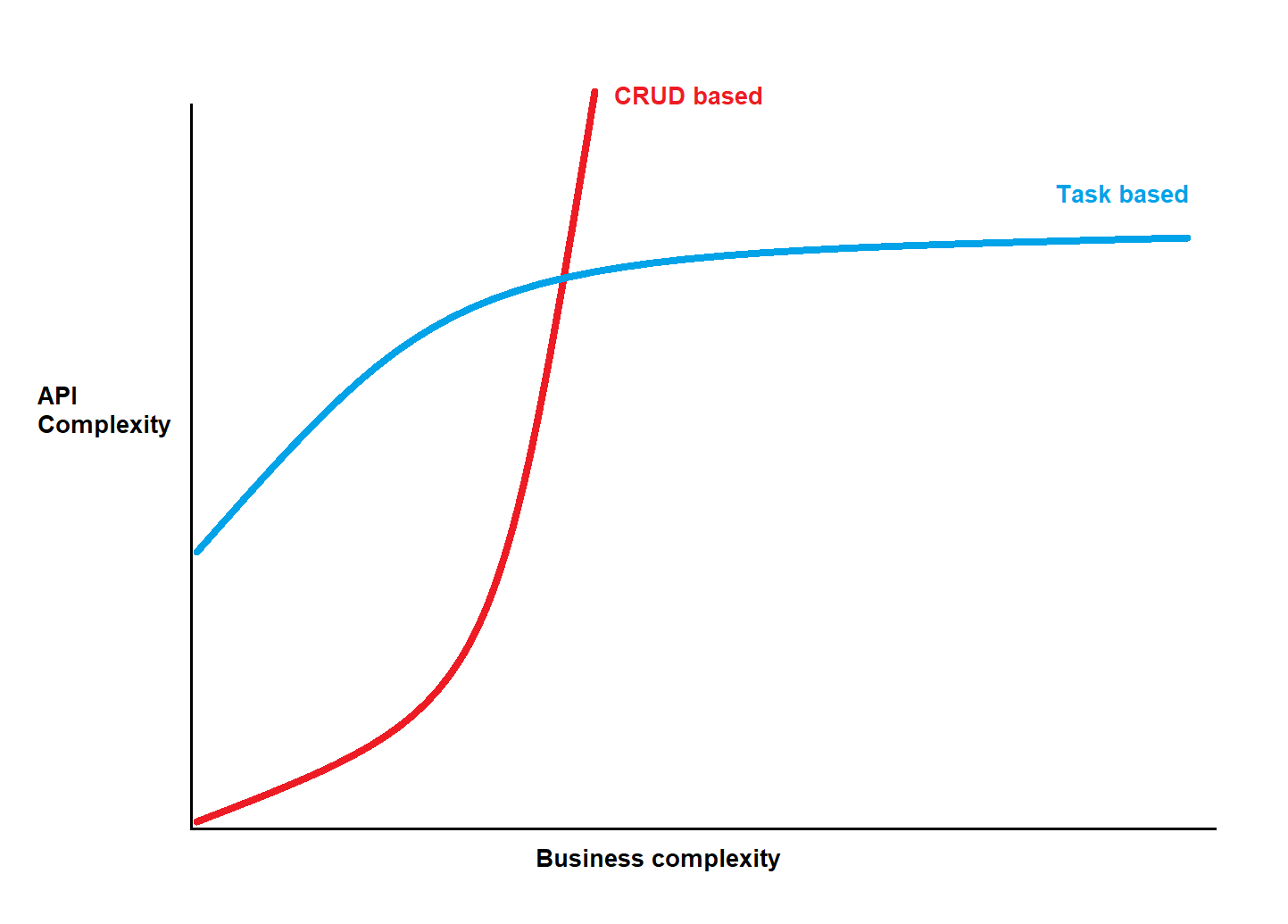
You’ll find this kind of schema in the IT world to compare the complexity of the domain centric vs data centric or the complexity between aenemic vs rich model. Or even the learning curve between DDD and the “classic” approach. It’s normal because all those topics are related.
- CRUD based will offer the same model for all operations.
- CRUD based is easier to develop while there is no complex business logic.
- CRUD based could be easily replaced with some storage mechanism providing an API.
- Task based will guide the user (UI) or the consumer (API) during an action.
- Task based let the system know the user’s intent (and this one bring multiple benefits).
- Task based will use smaller models (and this one bring multiple benefits).
- CQRS document - Greg Young: Not so long document talking about the task based UI, CQRS and event sourcing.