 Mithril
Mithril
Wouldn't you lock your door when you're away? Do the same with your data!

In my previous post I talked a little bit about the lost update problem which can be minimized when working with task based API. But you can never consider this problem as totally solved while you do not lock your data!
So first, let’s remember the issue.
Let’s say we have an app to manage the grocery list for a family, a classical web application with a web API behind it.
On that list the whole family indicate they need 2 bags of their favorite crisps (not gonna judge that). The rules in the family is simple: If you eat one bag you add a new one to the list.
Bob is watching a movie while eating a bag of crips and as soone as this one is finished, he opens the application, sees there are already 2 to buy and makes it 3. But Raymond was in another room eating another bag of crisps with some friends and did exactly the same than Bob (sees 2 and makes it 3) at the same time.
So with no locking system, which amount of bag of crips the application will show next time? It will depends on how the API is designed: Maybe 3 if the API just receive the new number of bag of crisps):
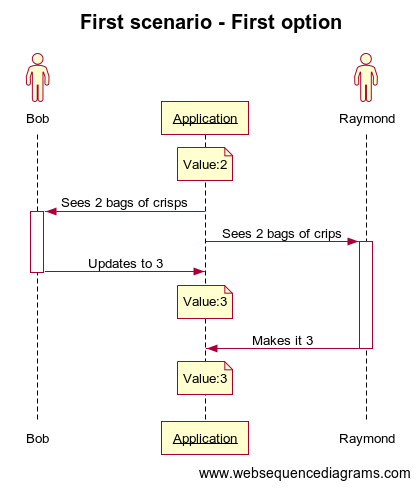
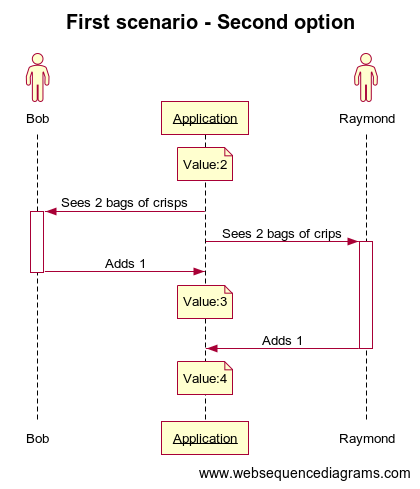
Here we’re saved if the API choose the second option (add x elements instead of update the number) but does this mean we can avoid to lock our data?
Dad is cooking and notice the family has finished the last bottle of olive oil. He’s busy so he can’t add it himself to the grocery list so he’s screaming “Can someone add 1 bottle of olive oil to the list ?”.
Bob hears that and opens the application, sees there is no bottle of olive oil to the list and add 2. You know the drill, Raymond is doing exactly the same at the same time…
How many bottles of olive oil do we have on the list? Once again it will depend… : Maybe 2 if the API just received the new number of bottle:
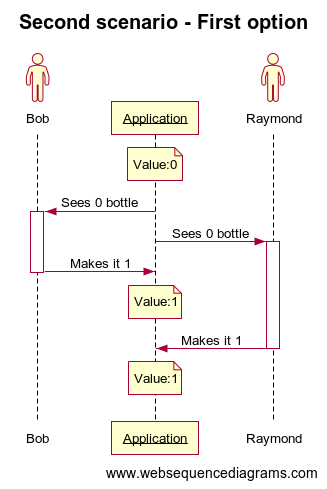
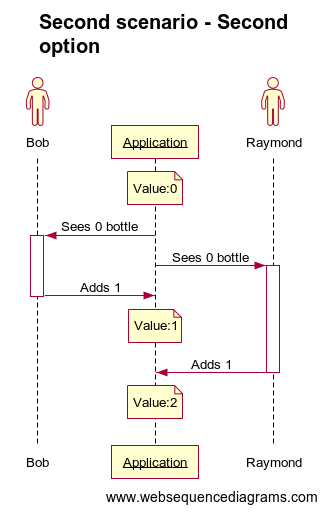
No matter how good you design your API you will have some concurrency issues when two timeframes (also known as sessions) overlap… And this could harm your data integrity. Either with the first way of doing (send the new number of item) which can result in a lost update in the first scenario. Or with the second way (add new elements to the existing ones) which is not a lost update but can lead to unwanted state in the second scenario.
The previous example can seem silly but imagine the same kind of issue with a critical system like health care, banking or payment?
You obviously could argue “the timeframe is so small it could never happens” but it would be throwing out one of the golden rules of concurrency: you can never assume how fast or slow things will happen… So if there is even a tiny timeframe where it’s possible to have those issues then your data integrity is not safe.
And also this tiny timeframe is maybe not as tiny as you may think… In the previous example the timeframe is about minutes… But any family member could open the application in a browser and let it open for hours especially if you do not have any live update mechanism to keep the information up the date on the screen!
But is it a real problem if your application does not manage those issues? Your business has to decide about that. You should explain them the possible cases and they will put into balance the different issues it could bring, together with the time of development of the solution and the disagreement those solutions could bring to the users. In all cases the business has to be warned about this!
We have to implement a way to ensure we are updating things based on the right/latest data and we can do that by locking the data.
It’s possible that you think about database transactions as a way to lock your records. It’s indeed a form of locking but it’s slightly different so I will talk about that later in this post.
For the following let’s just assume we have the classic stuff: Web application/Mobile application -> Web API -> Storage.
As the name suggests we will gonna be optimistic but optimistic about what? About the probablity to have conflict.
This mechanism is the most common, all you need to do is to put a version number with your data.
Each time a user will ask for the data you will provide the data with the current version number.
When the user makes an update, they will have to provide the version number they are using… In case data was updated by someone else, the version number will be outdated and the update will be rejected.
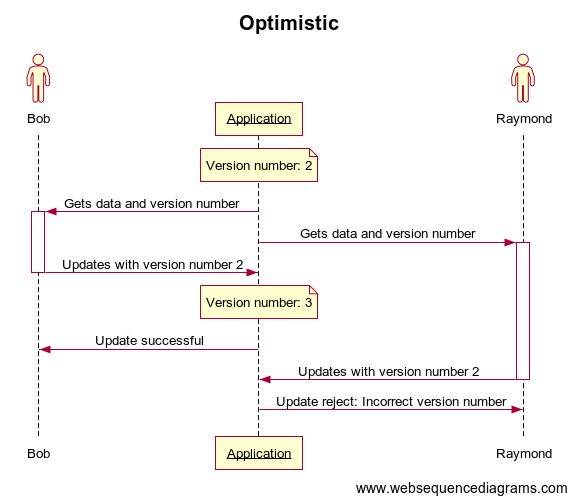
What does ‘rejected’ mean? You’re warning the user the update is not possible because the data he got are not the latest one and it’s possible it provokes a conflict (it’s not because someone updates the data before you a conflict will occur). Then you can either revert the change (not really user friendly) or propose to the user to merge his changes whith the latest data (more user friendly but will cost more in development since there could be multiple types of conflict).
Revert and merge are some words you commonly heard/used with versionning system like Git. It’s because Git is also using an optimistic offline locking!
You get the latest branch commit from the server and you start to create yours locally. When you try to push your new commits to the server, if another user pushed a new commit before you, you’d get an error because you need to update your branch locally before pushing your owns commit. This doesn’t mean you will have a conflict each time but it’s always possible.
As stated in Martin Fowler’s book about patterns, you could use timestamp instead of a version number but as he said, it’s maybe not a good idea if multiple servers are involved. Each server has its own time and even with time synchronization (by example with NTP) there is always a slight difference depending on the network quality. My knowledge about this topic is really limited so maybe has this issue been solved?
And as you maybe wonder: Yes, the optimistic offline locking is not a real lock since no data are locked in this mechanism!
In a classical relational database the recipe is not complicated:
- Put a version number for each record.
- Send the version number each time a user requests data.
- When a update is incoming with the version number, use this version number in the “where” clause.
This is really simple but has a drawback… How do you determine the root cause if an update fails? Is it because the data you want to update does not exist (wrong identifier) or because the version number is not up to date? If you want to make such distinction, you need a slightly different scenario.
- When a update is incoming: Open a transaction on the database.
- Get the data based on the identifier.
- Check the version number at the API level.
- If everything is OK, do your update and commit the whole transaction.
If you don’t do the previous steps in a transaction, you can never be sure that, between the time you get the data and the time you modify them, noboby has made any change… Yes, the timeframe will be reduced in milliseconds but as stated before: If this timeframe exists, no matter its duration, you cannot ensure your data integrity.
But can you really be sure you solved the “lost update” issue? You provide the version number to API’s consumers (your web application or an external consumer) and they send it back to you during an update… But what if the consumer just tries to increase the version number until it works? Never trust user input! Here of course we’re not talking about “bad luck” but a real willing to bypass a security mechanism but if your data are critical enough to lock them, you should also care about malicious request… There are multiple ways to prevent that.
You can use a GUID in addition of the version number: You still get the information about the version and the GUID will ensure no one can guess the next one you will generate.
You can also prevent that by sending your version number hashed or encrypted! In this case the consumer will have in his hand a version number with no real meaning and will not be able to increment it since he doesn’t know which is the current value or how to hash to new one.
Goods news is sometimes the storage itself will help you. Either by providing the entire mechanism or by providing you some way to ease the implementation:
- For example Event Store is a storage for events so more oriented for event sourcing and it has such mechanism. When you upload an event you can (if you want) tell the storage wich version number (= number of events) you expect to have in your stream.
- SQL Server’s row version is a column type that is automatically updated each time the record is updated.
- I’m pretty sure there is a lot more but I don’t know each one of them :-)
If you’re pessimistic (meaning you consider it’s likely to have some conflicts) the optimistic locking could not be the solution. If you have a lot of people updating the same data you may have a lot of conflicts and it will not really be user friendly to tell your user its 4th update in a row failed again.
In that case the pessimistic offline locking could be the solution. In this mechanism you will not add a version number but add a flag to indicate if the data is locked or not.
When a user consults the data he will acquire the lock. What if a second user tries to get the same data from the API? It depends on the level of locking you need.
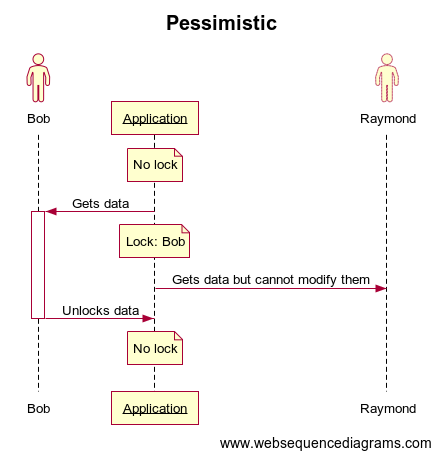
Excluvise write locking will ensure the first user to get the data will be the only one able to write it… In that case the second user will get the data but will be informed he didn’t get the lock on IT so the interface should not be editable.
Exclusive read locking you’ll totally prevent the second user to get the data if the first user read it and locked it earlier. This kind of locking should be used in case it’s better not to have data at all instead of potentially wrong data.
As you can guess it can be really frustrating for the second user because he will not be able to update or even see the data… I assume we all got that case where you’re not able to open/modify a shared file because some coworker forgot to close it? But in the same way the “locking or not locking?” question should be solved by the business (with all explanation in hands), the question about the type of locking should also be answered by them.
In a classical relational database the recipe is not more complicated than the optimistic offline locking: You can add a flag to your record but a boolean will not be enough… Yes, the boolean indicates data is locked but… How to ensure the person that modifies the data is the one who locked it?
So the username could be an option… But what if the same user opens the data twice? Once, one hour ago and twice, one minute ago? Maybe the first version is not the latest one so using his username as a check for the lock is not enough.
In this case you could either combine the version number and the username or using a GUID. In both cases we ensure the updater is the right one with the right version of the data.
But even if you use a GUID I think it’s a good idea to have the fields below (even if there are not directly used to check the lock):
- Version number: The user can know if he’s one version late or version 15-35-….
- Username: To know who lock the data.
- Timestamp: To know when the data was locked.
But you should not forget this warning, as for the optimistic offline locking, you should use a database transaction for that. When you read the data from the API:
- Get the data from the database.
- Check if the data is locked.
- Add a lock if possible. Warn the application if the user has the lock or not.
If those steps are not done in a transaction, you can’t be sure someone else didn’t acquire the lock after your first step. You’ll have the same warning for the update. You need to ensure your user still has the lock (maybe some mechanism could disable that lock like an administration super power).
The implementation for the exlusive write or exlusive read will be more or less the same: The exclusive write will warn the second user he didn’t get the lock and the application should not allow to edit the data (but since you can’t trust the client application or the consumer you need to always check the lock in the API) and for the exclusive read the data should not be returned at all if the lock is already set.
Deadlock is also possible in this case… Maybe two users will need to consult/modify customers “A” and “B”. The first one will acquire the lock on folder “A” and the second one will acquire lock on folder “B”. They will each wait to have the lock on the other folder but it will never happen. In that case indicate which user has currently the lock can be a good idea if it’s not a confidential information.
But if you implement it you should seriously consider some mechanism to avoid a too long locking, for example, if the user quits the application improperly, the application will not be able to warn the API the data has to be unlocked. You can e.g. set a lock duration (based of the lock timestamp) or have an administrator right to unlock data.
I talked about database transaction in some cases. Such mechanism can be used in relational databases or in NoSQL databases. But isn’t such transaction (with appropriate level) a kind of pessimistic locking?
You get the data in your API and depending on the isolation level you require, the data will be either unmodifiable or unreadable for other users. Yes, it’s indeed a pessimistic locking. But as you may have noticed when I was talking about locking, I always talked about “offline” locking… What does it mean?
When you have a transaction with your database you have an “online” session. You still use the same connection all along (which assume your session will be short).
In the scenario we talked about, we were in “offline” session. We got the data (maybe one hour ago) with one HTTP call which is finished (maybe the TCP connection’s still alive but only for performance purposes). The next HTTP call to update data will be a new one, not related to the previous ones.
It’s because HTTP is considered as a stateless protocol, meaning its requests should be isolated from the other ones… Of course, most frameworks offer you the possibility to manage an HTTP session (which is not the same as the previous session/timeframe) but the purpose of that is obviously not to create a constant connection to the database. It’s mainly for authentication purposes with cookies (if you’re using OAuth and a JWT token you don’t need a session anymore) or for statistical purposes.
- Two sessions at the same time can break data integrity (lost update).
- 2 kind of locking to avoid that: Optimistic or pessimistic.
- Optimistic is when the probablity of conflict is low so we let everyone read and update. The first one to update wins and the next ones are notified of the failure.
- Pessimistic is when the probability of having conflict is higher and has 2 variants : Exclusive write or Exclusive read.
- Pessimistic with exclusive write: The user reading the data got a lock that ensures him he will be the only one to edit them.
- Pessimistic with exclusive read: The user reading the data got a lock that ensures him nobody else can read the data until he unlocks it.
- Type of locking (or not) should be decided by the business based on the criticality of the data, the probability of conflict and the user experience.
- Never trust user input (again): It’s not because your client application will handle something you shouldn’t implement it in your API.